今晚索尼释出了一段重磅采访视频,主角是PlayStation首席架构师Mark Cerny与AMD计算与图形事业部总经理Jack Huynh。在这场深度对谈中,双方首次公开了代号为“紫水晶计划(Project Amethyst)”的合作项目,透露了多项将用于PS6等未来硬件的前沿技术,信息量极大!

从采访内容来看,PS6绝非一次简单的性能迭代,而是一次从架构层面彻底革新的“跨代飞跃”。Mark Cerny和Jack Huynh透露的技术方向,几乎重新定义了游戏主机的渲染和计算能力。我们来划一下重点:
一、整合型AI引擎:Neural Arrays(神经阵列)
核心思路:不再让GPU中的计算单元(CUs)“单打独斗”,而是将它们高效互联,形成一个可协同执行AI任务的专用阵列。
带来的提升:
- 机器学习性能大幅提升,支持更复杂的FSR、PSSR等超分与重建技术;
- 实现更高质量实时图像放大与去噪,画面更清晰、帧数更稳定;
- GPU具备更强AI推理能力,甚至可实现实时智能渲染与光线重建。
说人话:GPU里直接塞进一个“AI协处理器”,神经网络任务不再挤占图形资源。
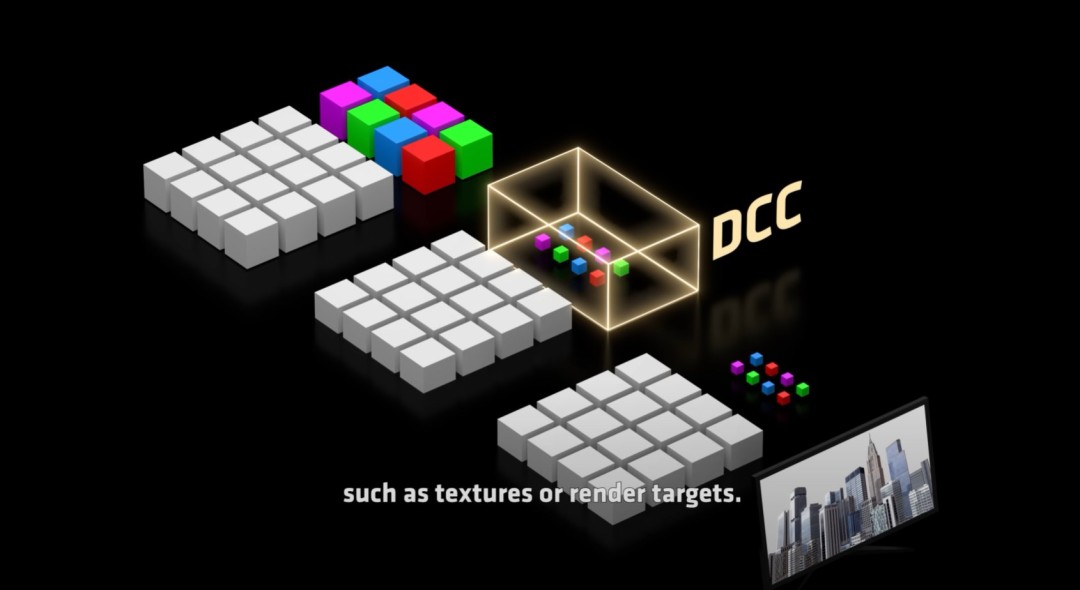
二、全新显存管理系统:Universal Compression(通用压缩)
核心思路:不只是压缩纹理,而是对所有写入显存的数据进行实时评估与压缩,极大节省带宽。
带来的提升:
- 显存带宽利用率大幅提高,同等硬件条件下实现更强性能;
- 支持更高精度贴图与更复杂场景,画面细节再升级;
- 整体功耗下降,主机运行更安静、能效比更高。
说人话:数据传输不再“铺张浪费”,带宽用在刀刃上,主机干活更聪明。
三、专用光线追踪硬件:Radiance Cores(辐射核心)
核心思路:在GPU中集成独立硬件单元,专职处理光线遍历与路径追踪,彻底解放着色核心与CPU。
带来的提升:
- 光追性能实现数量级提升,路径追踪也可流畅运行;
- CPU不再被光追任务拖累,可更专注于物理、AI模拟等;
- 渲染管线更简洁高效,整体帧率与稳定性显著增强。
说人话:光线追踪从此不再是“帧数杀手”,实时光影效果逼近电影级。
四、三大系统协同优化:Neural Arrays × Radiance Cores × Universal Compression
协同意义:
- AI可辅助光追进行智能去噪与重建,画面更干净;
- 压缩技术缓解带宽压力,让AI与光追同时高负载运行成为可能;
- 整体能效控制更出色,性能提升的同时发热与噪音反而降低。
说人话:三大模块如大脑、心脏、肺协同工作,效率倍增,这才是真正的次世代架构。
五、其他潜在改进方向(推测)
- 更快的SSD与I/O系统,实现真正无缝加载与场景切换;
- 改进散热与能耗管理,维持高性能同时控制噪音与发热;
- 电影级渲染管线整合AI重建、全局光照与混合追踪技术;
- 更强开发者工具与开放API,提升跨平台开发效率。
六、发售窗口预期
PS6预计发售时间:2028年左右
当前状态:所有技术仍处于“模拟验证阶段”,尚未进入实际量产。

一句话总结:
PS6不再只是一台“更强的游戏机”,而是一台具备AI思维、能理解光线与图像的协同计算设备。它带来的不仅是画面进步,更是游戏开发与体验方式的根本变革。
📝 采访技术细节整理
索尼与AMD联合推出全新神经引擎“Neural Arrays”:整合所有GPU计算单元
Mark Cerny与Jack Huynh在采访中提到:
“像FSR和PSSR这类技术所使用的神经网络,对GPU负载极其沉重。它们既需要大量计算资源,又必须高速访问内存。而传统GPU由大量计算单元(CUs)组成,任务往往被拆得太碎,带来效率损失,甚至迫使我们放弃某些实现方式。”
“我们提出的‘Neural Arrays’技术,其核心理念是让计算单元能共享数据、协同工作,像一个专注的AI引擎一样协作。我们是在每个着色器引擎内部,通过高效的方式将计算单元互联。这改变了神经渲染的游戏规则——我们可以使用更大的机器学习模型,降低开销,并在负载增长时实现更强的扩展性。”
“这项技术让我们能一次性处理屏幕上的大块区域,效率的提升将是革命性的。”
通用压缩(Universal Compression):不只是纹理,是所有数据
Cerny特别强调了带宽的重要性:
“无论是机器学习还是光追,都受限于显存带宽。我们目前的DCC技术只压缩部分数据,而‘通用压缩’则评估每一份即将写入显存的数据,在可能的情况下全部压缩。只有必要的字节才会被传输,带宽占用大幅降低。”
“这将带来更精细的画面、更高帧率与更高能效。我们非常期待它实际表现出的带宽增益,以及它如何与Neural Arrays、Radiance Cores协同工作。”
辐射核心(Radiance Cores):光追不再占用着色资源
关于专用光追硬件,Cerny解释:
“辐射核心完全接管了光线遍历这一最耗算力的环节。通过硬件专门处理,CPU被解放用于几何与物理模拟,GPU则可专注着色与光照。结果就是一个更简洁、高速、高效的渲染管线。”
“将遍历逻辑硬件化本身就能带来巨大性能飞跃,而独立于着色核心运行又进一步提升效率。我们还在开发更灵活的数据结构以优化光追处理。”